PS: 爬虫不进入 img_url 函数的小伙伴儿 请尝试将将代码复制到你新建的 py 文件中。 2017/8/30 更新解决了网站防盗链导致下载图片失败的问题
1 2 3
D :cd PycharmProjects scrapy startproject mzitu_scrapy
我是 Windows!其余系统的伙伴儿自己看着办哈。 这都不会的小伙伴儿,快去洗洗睡吧。养足了精神从头看一遍教程哈! 在 PyCharm 中打开我们的项目目录。 在 mzitu_scrapy 目录创建 run.py。写入以下内容:
1 2
from scrapy.cmdline import execute execute(['scrapy', 'crawl', 'mzitu'])
其中的 mzitu 就为待会儿 spider.py 文件中的 name 属性。这点请务必记住哦!不然是跑不起来的。 在 mzitu_scrapy\spider 目录中创建 spider.py。文件作为爬虫文件。 好了!现在我们来想想,怎么来抓 mzitu.com 了。 首先我们的目标是当然是全站的妹子图片!!! 但是问题来了,站长把之前那个 mzitu.com\all 这个 URL 地址给取消了,我们没办法弄到全部的套图地址了! 我们可以去仔细观察一下站点所有套图的地址都是:http://www.mzitu.com/ 几位数字结尾的。 这种格式地址。 有木有小伙伴儿想到了啥? http://www.mzitu.com/ 几位数字结尾的” 这种格式的 URL 了。 Go Go Go Go!开始搞事。
1 2 3 4 5 6 7 8 9 10
import scrapy class MzituScrapyItem(scrapy.Item): name = scrapy.Field() image_urls = scrapy.Field() url = scrapy.Field() pass
第一步完成啦!开始写 spider.py 啦! 首先导入我们需要的包:
1 2 3 4
from scrapy import Requestfrom scrapy.spider import CrawlSpider, Rule from scrapy.linkextractors import LinkExtractorfrom mzitu_scrapy.items import MzituScrapyItem
都是干啥的我不说了哈!不知道的小伙伴儿自己去翻翻官方文档。 接下来是:
1 2 3 4 5 6 7 8
class Spider(CrawlSpider): name = 'mzitu' allowed_domains = ['mzitu.com' ] start_urls = ['http://www.mzitu.com/' ] img_urls = [] rules = ( Rule(LinkExtractor(allow=('http://www.mzitu.com/\d{1,6}' ,), deny=('http://www.mzitu.com/\d{1,6}/\d{1,6}' )), callback ='parse_item' , follow =True ), )
第五行的 img_urls=[] 这个列表是我们之后用来存储每个套图的全部图片的 URL 地址的。 rules 中的语句是:匹配 http://www.mzitu.com/1 至 6 位数的的 URL(\\d:数字;{1,6} 匹配 1 至 6 次。就能匹配出 1 到 6 位数) 但是我们会发现网页中除了 http://www.mzitu.com/XXXXXXX 这种格式的 URL 之外;还有 http://www.mzitu.com/XXXX/XXXX 这个格式的 URL。所以我们需要设置 deny 来不匹配 http://www.mzitu.com/XXXX/XXXX 这种格式的 URL。 然后将匹配到的网页交给 parse_item 来处理。并且持续追踪 看这儿敲黑板!!划重点!!:::
重点说明!!!!不能 parse 函数!!这是 CrawlSpider 进行匹配调用的函数,你要是使用了!rules 就没法进行匹配啦!!! 现在 spider.py 是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
from scrapy import Requestfrom scrapy.spider import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorfrom mzitu_scrapy.items import MzituScrapyItemclass Spider (CrawlSpider) : name = 'mzitu' allowed_domains = ['mzitu.com' ] start_urls = ['http://www.mzitu.com/' ] img_urls = [] rules = ( Rule(LinkExtractor(allow=('http://www.mzitu.com/\d{1,6}' ,), deny=('http://www.mzitu.com/\d{1,6}/\d{1,6}' )), callback='parse_item' , follow=True ), ) def parse_item (self, response) : print(response.url)
来跑一下试试 别忘了怎么测试的哈!!上面新建的那个 run.py! http://www.w3school.com.cn/ 看看 xpath 的教程! 当然你直接用 Chrome 拷贝出来的那个 xpath 也行。(有一定的概率不能使) 现在来找图片地址了,怎么找我在 小白爬虫第一弹中已经写过了哈!这就不详细赘述了! 首先找到每套图有多少张图片:
1
descendant::div [@class ='main' ]/div [@class ='content' ]/div [@class ='pagenavi' ]/a[last()-1 ]/span/text()
意思是选取根节点下面所有后代标签,在其中选取出 div [@class=’main’] 下面的 div [@class=’content’] 下面的 /div [@class=’pagenavi’] 下面的倒数第二个 a 标签 下面的 span 标签中的文本。(有点长哈哈哈哈哈!其实还可以短一些,我懒就不改了) 然后循环拼接处每张图片的的网页地址,现在 spider.py 是这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
from scrapy import Requestfrom scrapy.spider import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorfrom mzitu_scrapy.items import MzituScrapyItemclass Spider (CrawlSpider) : name = 'mzitu' allowed_domains = ['mzitu.com' ] start_urls = ['http://www.mzitu.com/' ] img_urls = [] rules = ( Rule(LinkExtractor(allow=('http://www.mzitu.com/\d{1,6}' ,), deny=('http://www.mzitu.com/\d{1,6}/\d{1,6}' )), callback='parse_item' , follow=True ), ) def parse_item (self, response) : """ :param response: 下载器返回的response :return: """ item = MzituScrapyItem() max_num = response.xpath("descendant::div[@class='main']/div[@class='content']/div[@class='pagenavi']/a[last()-1]/span/text()" ).extract_first(default="N/A" ) item['name' ] = response.xpath("./*//div[@class='main']/div[1]/h2/text()" ).extract_first(default="N/A" ) for num in range(1 , int(max_num)): page_url = response.url + '/' + str(num) yield Request(page_url, callback=self.img_url)
extract_first (default=”N/A”) 的意思是:取 xpath 返回值的第一个元素。如果 xpath 没有取到值,则返回 N/A 然后调用函数 img_url 来提取每个网页中的图片地址。img_url 长这样:
1 2 3 4 5 6 7 8
def img_url (self, response,) : """取出图片URL 并添加进self.img_urls列表中 :param response: :param img_url 为每张图片的真实地址 """ img_urls = response.xpath("descendant::div[@class='main-image']/descendant::img/@src" ).extract() for img_url in img_urls: self.img_urls.append(img_url)
descendant::div [@class=’main-image’]/descendant::img/@src 这段 xpath 取出 div [@class=’main-image’] 下面所有的 img 标签的 src 属性(有的套图一个页面有好几张图) .extract () 不跟上 [0] 返回的是列表 完整的 spider.py 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42
from scrapy import Requestfrom scrapy.spider import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorfrom mzitu_scrapy.items import MzituScrapyItemclass Spider (CrawlSpider) : name = 'mzitu' allowed_domains = ['mzitu.com' ] start_urls = ['http://www.mzitu.com/' ] img_urls = [] rules = ( Rule(LinkExtractor(allow=('http://www.mzitu.com/\d{1,6}' ,), deny=('http://www.mzitu.com/\d{1,6}/\d{1,6}' )), callback='parse_item' , follow=True ), ) def parse_item (self, response) : """ :param response: 下载器返回的response :return: """ item = MzituScrapyItem() max_num = response.xpath("descendant::div[@class='main']/div[@class='content']/div[@class='pagenavi']/a[last()-1]/span/text()" ).extract_first(default="N/A" ) item['name' ] = response.xpath("./*//div[@class='main']/div[1]/h2/text()" ).extract_first(default="N/A" ) item['url' ] = response.url for num in range(1 , int(max_num)): page_url = response.url + '/' + str(num) yield Request(page_url, callback=self.img_url) item['image_urls' ] = self.img_urls yield item def img_url (self, response,) : """取出图片URL 并添加进self.img_urls列表中 :param response: :param img_url 为每张图片的真实地址 """ img_urls = response.xpath("descendant::div[@class='main-image']/descendant::img/@src" ).extract() for img_url in img_urls: self.img_urls.append(img_url)
下面开始把图片弄回本地啦!! 开写我们的 pipelines.py 首先根据官方文档说明我们如果需要使用图片管道 则需要使用 ImagesPipeline:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64
from scrapy import Requestfrom scrapy.pipelines.images import ImagesPipelinefrom scrapy.exceptions import DropItemimport reclass MzituScrapyPipeline (ImagesPipeline) : def file_path (self, request, response=None, info=None) : """ :param request: 每一个图片下载管道请求 :param response: :param info: :param strip :清洗Windows系统的文件夹非法字符,避免无法创建目录 :return: 每套图的分类目录 """ item = request.meta['item' ] folder = item['name' ] folder_strip = strip(folder) image_guid = request.url.split('/' )[-1 ] filename = u'full/{0}/{1}' .format(folder_strip, image_guid) return filename def get_media_requests (self, item, info) : """ :param item: spider.py中返回的item :param info: :return: """ for img_url in item['image_urls' ]: referer = item['url' ] yield Request(img_url, meta={'item' : item, 'referer' : referer}) def item_completed (self, results, item, info) : image_paths = [x['path' ] for ok, x in results if ok] if not image_paths: raise DropItem("Item contains no images" ) return item def strip (path) : """ :param path: 需要清洗的文件夹名字 :return: 清洗掉Windows系统非法文件夹名字的字符串 """ path = re.sub(r'[?\*|“<>:/]' , '' , str(path)) return path if __name__ == "__main__" : a = '我是一个?*|“<>:/错误的字符串' print(strip(a))
写一个中间件来处理图片下载的防盗链:
1 2 3 4 5 6 7 8 9 10 11
class MeiZiTu (object) : def process_request (self, request, spider) : '''设置headers和切换请求头 :param request: 请求体 :param spider: spider对象 :return: None ''' referer = request.meta.get('referer' , None ) if referer: request.headers['referer' ] = referer
最后一步设置 ImagesPipeline 的存储目录! 在 settings.py 中写入:
1
IMAGES_STORE = 'F:\mzitu\\'
则 ImagesPipeline 将所有下载的图片放置在此目录下! 设置图片实效性: 图像管道避免下载最近已经下载的图片。使用 FILES_EXPIRESIMAGES_EXPIRES
settings.py 中开启 item_pipelines:
1 2 3
ITEM_PIPELINES = { 'mzitu_scrapy.pipelines.MzituScrapyPipeline' : 300, }
settings.py 中开启 DOWNLOADER_MIDDLEWARES
1 2 3
DOWNLOADER_MIDDLEWARES = { 'mzitu_scrapy.middlewares.MeiZiTu' : 543, }
如果你需要缩略图之类的请参考官方文档: http://cuiqingcai.com/3443.html 做一个代理,就不需要重写 Scrapy 中间件啦!更能避免费代理总是不能用的坑爹行为。 总之省事省时又省心啊! github 地址:https://github.com/thsheep/mzitu_scrapy
 这几天一直有小伙伴而给我吐槽说,由于妹子图站长把 www.mzitu.com/all 这个地址取消了。导致原来的那个采集爬虫不能用啦。 正好也有小伙伴儿问 Scrapy 中的图片下载管道是怎么用的。 就凑合在一起把 mzitu.com 给重新写了一下。
这几天一直有小伙伴而给我吐槽说,由于妹子图站长把 www.mzitu.com/all 这个地址取消了。导致原来的那个采集爬虫不能用啦。 正好也有小伙伴儿问 Scrapy 中的图片下载管道是怎么用的。 就凑合在一起把 mzitu.com 给重新写了一下。  首先确保你的 Python 环境已安装 Scrapy!!!!!!!! 命令行下进入你需要存放项目的目录并创建项目: 比如我放在了 D:\PycharmProjects
首先确保你的 Python 环境已安装 Scrapy!!!!!!!! 命令行下进入你需要存放项目的目录并创建项目: 比如我放在了 D:\PycharmProjects CrawlSpider !!!就是这玩儿!! 有了它我们就能追踪 “http://www.mzitu.com/ 几位数字结尾的” 这种格式的 URL 了。 Go Go Go Go!开始搞事。
CrawlSpider !!!就是这玩儿!! 有了它我们就能追踪 “http://www.mzitu.com/ 几位数字结尾的” 这种格式的 URL 了。 Go Go Go Go!开始搞事。  首先在 item.py 中新建我们需要的字段。我们需要啥?我们需要套图的名字和图片地址!! 那我们新建三个字段:
首先在 item.py 中新建我们需要的字段。我们需要啥?我们需要套图的名字和图片地址!! 那我们新建三个字段: Good!!真棒!全是我们想要的!!! 现在干啥?啥?你不知道?EXM 你没逗我吧!
Good!!真棒!全是我们想要的!!! 现在干啥?啥?你不知道?EXM 你没逗我吧! 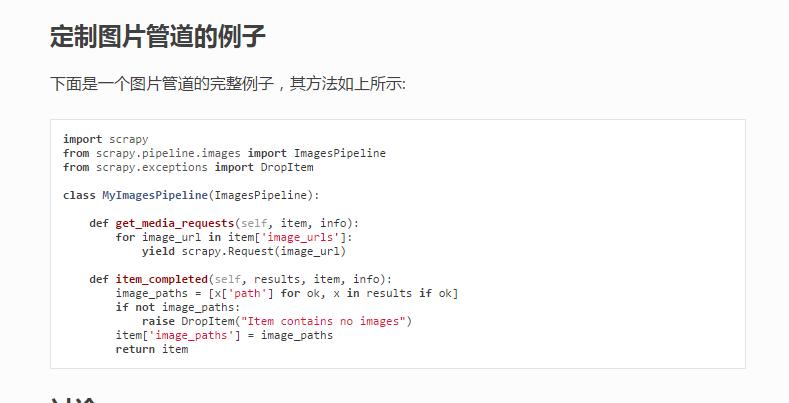 当然是解析我们拿到的 response 了!从里面找我们要的套图名称和所有的图片地址了! 我们随便打开一个 URL。 首先用 xpath 取套图名称: 啥?你不知道怎么用 xpath??少年少女 你走吧。出去别说看过我的博文。 ./*//div [@class=’main’]/div [1]/h2/text () 这段 xpath 就是套图名称的 xpath 了!看不懂的少年少女赶快去 http://www.w3school.com.cn/ 看看 xpath 的教程! 当然你直接用 Chrome 拷贝出来的那个 xpath 也行。(有一定的概率不能使) 现在来找图片地址了,怎么找我在 小白爬虫第一弹中已经写过了哈!这就不详细赘述了! 首先找到每套图有多少张图片:
当然是解析我们拿到的 response 了!从里面找我们要的套图名称和所有的图片地址了! 我们随便打开一个 URL。 首先用 xpath 取套图名称: 啥?你不知道怎么用 xpath??少年少女 你走吧。出去别说看过我的博文。 ./*//div [@class=’main’]/div [1]/h2/text () 这段 xpath 就是套图名称的 xpath 了!看不懂的少年少女赶快去 http://www.w3school.com.cn/ 看看 xpath 的教程! 当然你直接用 Chrome 拷贝出来的那个 xpath 也行。(有一定的概率不能使) 现在来找图片地址了,怎么找我在 小白爬虫第一弹中已经写过了哈!这就不详细赘述了! 首先找到每套图有多少张图片:  就是红框中的那个东东。 Xpath 这样写:
就是红框中的那个东东。 Xpath 这样写: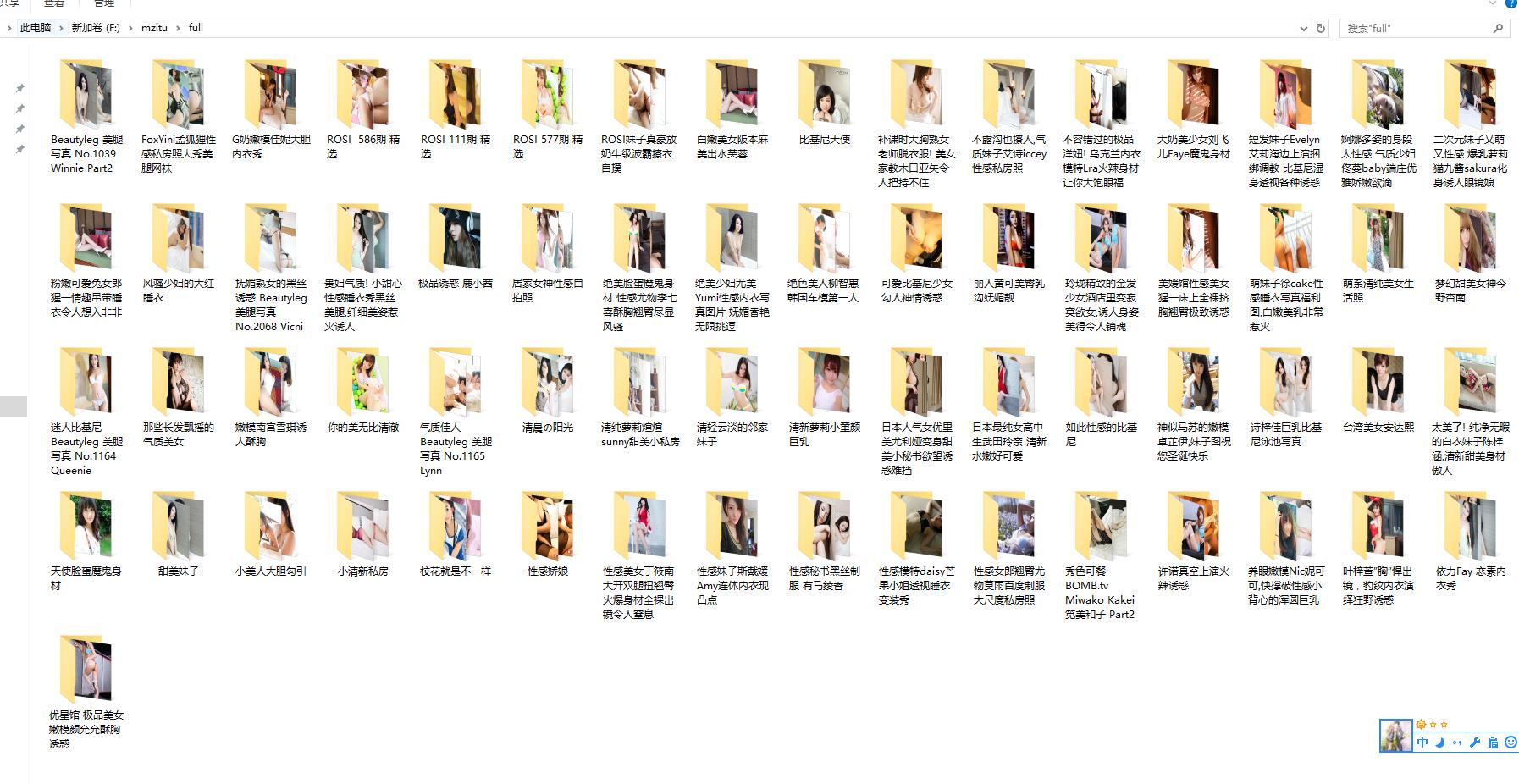 我们可以依葫芦画瓢写一个。但是这样有一个很麻烦的问题就是,这样下载下来的图片没有分类,很是难看啊! 所以 我们需要重写一下 ImagesPipeline 中的 file_path 方法! 具体如下:
我们可以依葫芦画瓢写一个。但是这样有一个很麻烦的问题就是,这样下载下来的图片没有分类,很是难看啊! 所以 我们需要重写一下 ImagesPipeline 中的 file_path 方法! 具体如下: 将其写入 settings.py 文件中。 至此完毕!!! 来看看效果:
将其写入 settings.py 文件中。 至此完毕!!! 来看看效果:  下载速度简直飞起!!友情提示:请务必配置代理哦! 可以参考大才哥的 http://cuiqingcai.com/3443.html 做一个代理,就不需要重写 Scrapy 中间件啦!更能避免费代理总是不能用的坑爹行为。 总之省事省时又省心啊! github 地址:https://github.com/thsheep/mzitu_scrapy
下载速度简直飞起!!友情提示:请务必配置代理哦! 可以参考大才哥的 http://cuiqingcai.com/3443.html 做一个代理,就不需要重写 Scrapy 中间件啦!更能避免费代理总是不能用的坑爹行为。 总之省事省时又省心啊! github 地址:https://github.com/thsheep/mzitu_scrapy


